Web applications can come and go, but once you have an application/service that starts gaining traction, your simple setup on shared hosting will eventually start to show its limits. The app you started has grown. It now uses a few third-party services and relies on more than a few libraries and packages. Your manual deployment processes have also grown and are now more prone to human error in the process. What can a developer do to start moving towards the path of more maintainability and scalability?
One proven way is the “Twelve-Factor App” methodology. This blog post will cover I-IV in the Twelve-Factor App methodology. Many of these twelve concepts are also building blocks towards building out even more complex systems like Kubernetes, but let’s not get ahead of ourselves. We can define our starting point as:
An application that:
- is a web application
- maybe already hosted/deployed on a service like Amazon’s AWS or Google Cloud
- needs a lot of manual attention, especially when updating production, managing application settings, and dealing with infrastructure changes.
As we step through all the different factors, we should keep in mind their benefits, both short and long-term, and how each concept leads to more maintainability and scalability. More importantly, though this is not exactly measurable, this should reduce your stress when dealing with this part of the application development cycle (no guarantees!).
At the end of this series, your app will (to mention a few):
- have a higher level of security when it comes to configurations and credentials used in your app
- have a more robust system for debugging issues
- be more resilient if services change
- be on a path towards more automated processes, such as build and deploy steps.
I. Codebase
One codebase tracked in revision control, many deploys - https://12factor.net/codebase
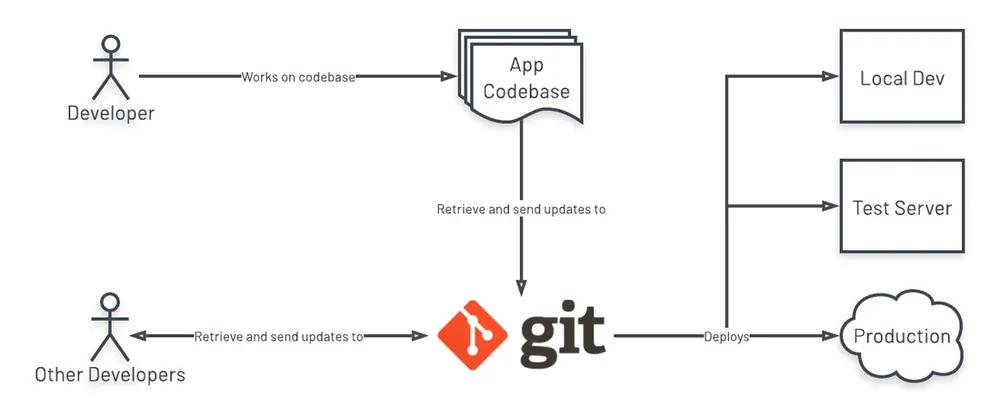
First up: your codebase. The soul of your application. On the surface, the concepts are pretty simple:
- code must be in a repository
- only one codebase per app
One codebase tracked in revision control ...
These days, you’re likely already using a code versioning system, and it will most likely be git.
There’s also other version control systems such as Subversion (svn)
or Mercurial hg). This post will use concepts as it relates to git.
If you’re not using a code versioning system on your project, you should stop reading this and start using one right now. It’s that important.
This acts as somewhat of a backup in case of data loss on your system and also has a number of other benefits like tracking historical code changes and ease of collaboration when a team is working on a single codebase. Pick a code versioning system (probably going to be git) and use a service like GitHub, GitLab, or even host your own.
One codebase ... many deploys
There’s some nuance with these specific words. They are highly subjective and might not apply in all situations, but here’s one way to look at it.
“One codebase” refers to a single app. For example, if you have a company blog and a customer management system in the same repository, that violates this rule. You will often need to give each project its own repo. Technically an app codebase can contain references to other codebases’ repositories ( see: git submodules), but the majority of the time you would want to define those as “dependencies”. This will be covered in the next section, section II.
“Many deploys” is where a developer must be mindful of what’s being committed into the repository. “One codebase … many deploys” can be interpreted as a single source of truth (your git repo) that all environments use. More importantly, all environments (development, production, test, etc) should be able to use the codebase as it is in the repo with very little intervention.
An example of this: you have an API backend. For testing purposes you've been including extra data for debugging each API response:
# Taken from https://fastapi.tiangolo.com/#example
@app.get('/items/{item_id}')
def get_item(item_id: int, q: Optional[str] = None):
return {
"id": item_id,
"q": q,
"debug": "I need this during development. Please ignore."
}
With “one code base … many deploys” this would be a problem. When deploying to a production environment, a developer
would need to remove the "debug" item every time production is updated. There are many frameworks that use some sort
of global variable to check if an application is running in production mode, but that will be covered later in section
III.
In this case, we want to ensure that these debug statements don’t appear. For now, we can rewrite the above as:
# Taken from https://fastapi.tiangolo.com/#example
@app.get('/items/{item_id}')
def get_item(item_id: int, q: Optional[str] = None):
ret = {
"id": item_id,
"q": q,
}
# Assuming there's a `DEBUG_MODE` global variable set in our app's config.
if DEBUG_MODE:
ret["debug"] = "I need this during development. Please ignore."
return ret
II. Dependencies
Explicitly declare and isolate dependencies - https://12factor.net/dependencies
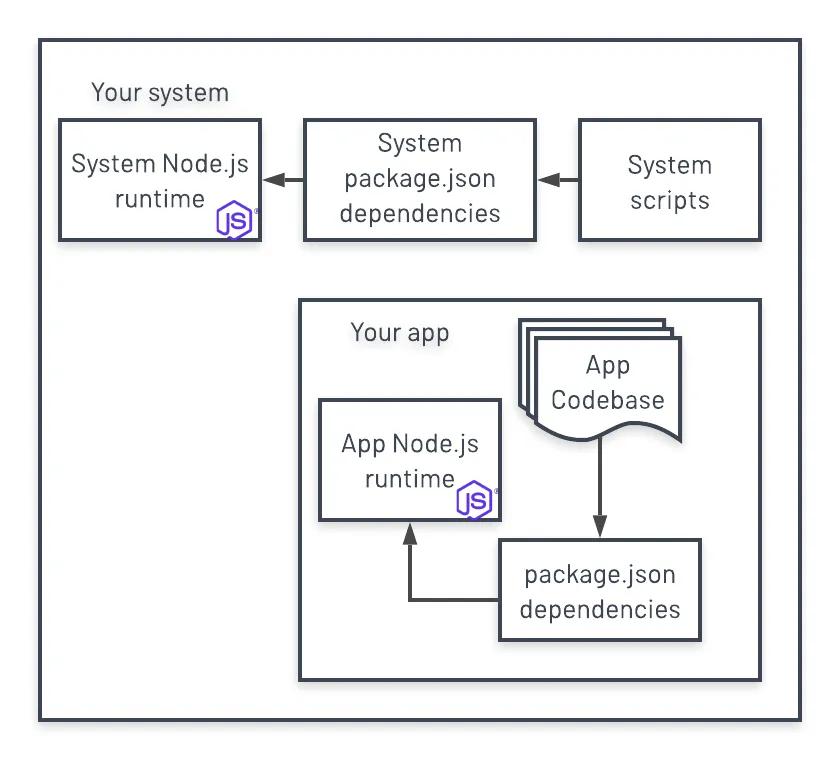
As with the last section, more modern development processes have this concept ingrained in their usage.
Why is declaring dependencies important? Reproducibility. Code deploys should be as identical as possible between environments. This is extremely important, for example, if someone were to debug production issues on their own local development setup.
For example, with Python it’s generally understood that pip is used for package management (with
a requirements.txt file) and virtualenv is used to isolate application dependencies
from system dependencies. More recently, this can also be done with newer tools
like Pipenv and Poetry.
Also, in the Javascript world, npm and yarn are both generally understood to be the main package management tools (
with package.json
and yarn.lock) and optionally nvm (or similar) can be used to select a Node runtime.
Python is especially significant in this section since it’s widely used in modern operating systems under the hood. In Linux, many system scripts use Python, which is why distributions are pinned to specific Python versions. Similarly, as of the time of writing, Macs include Python 2.7 as its main Python binary (/usr/bin/python) which has been deprecated since January 1, 2020 in order to keep compatibility with legacy software. If you want to run your app with a specific version of Python, especially newer versions, isolating your runtime and dependencies is a must.
Another way to isolate dependencies, though more involved and adds complexity, is to use Docker.
See Docker’s official documentation for more information. With
Docker, you will be able to completely isolate your runtime, application code, and its dependencies from your host (i.e.
your computer’s system dependencies) via containers. This also brings another level of reproducibility as
the Dockerfile defines all the steps necessary to bring up a working version of the app.
Using these tools to isolate your dependencies gives full visibility of what your app needs to run and build.
III. Config
Store config in the environment - https://12factor.net/config
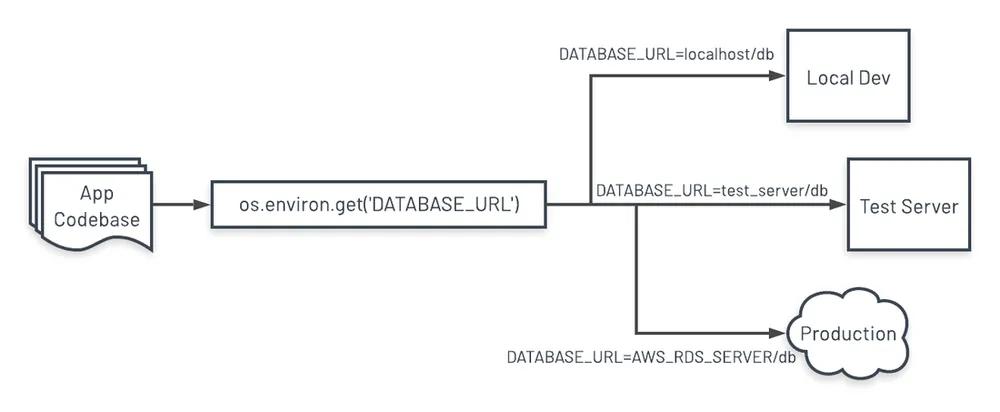
Application configs are a critical piece to this twelve-part puzzle. Since configs will definitely differ across environments, we need a way for our application’s configs to be more dynamic and change depending how it’s deployed. Not only will this streamline deployments, but it also has additional benefits such as securing sensitive data (i.e. database usernames and passwords) since that data is never committed into the source repo as code. This also helps satisfy requirements in section I.
Let’s look at an example:
# Taken from: https://fastapi.tiangolo.com/advanced/async-sql-databases/?h=async+datab#import-and-set-up-sqlalchemy
import databases
from fastapi import FastAPI
# Use in dev
# SQLAlchemy specific code, as with any other app
DATABASE_URL = "sqlite:///./test.db"
# Use in production
# DATABASE_URL = "postgresql://user:password@postgresserver/db"
database = databases.Database(DATABASE_URL)
With the above, you can see thatDATABASE_URL is hardcoded for both development and production cases, and we’ve exposed
our username and password in our code.
If this code were committed and open-sourced (or otherwise somehow made public), that would be a pretty significant security problem.
What can we do instead? Use environment variables.
Without going too deep into what environment variables (or env vars) are, we can think of them as variables that exist alongside your app. They are also accessible from your app, making them very useful as dynamic variables that change depending on your app’s runtime environment.
What are we working towards? Here’s the following from the official Twelve-factor App site:
A litmus test for whether an app has all config correctly factored out of the code is whether the codebase could be made open source at any moment, without compromising any credentials.
With our code above, we definitely don’t want that publicly available, so now let’s modify the above with
Python’s os.environ mapping, but first we need to define our
database env var:
# In our server’s shell, set the `DATABASE_URL` variable.
# `export` allows programs outside of this current shell session to use `DATABASE_URL`.
root@28b24b724f54:/# export DATABASE_URL="postgresql://mydbuser:mysecretpass@thePGserver/db"
# Let’s also set our environment type
root@28b24b724f54:/# export ENV=development
# Let’s see what Python would give us with `os.environ`.
root@ee16c88faf39:/# python
Python 3.6.14 (default, Jul 22 2021, 16:21:31)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import os
>>> os.environ
environ({
'DATABASE_URL': 'postgresql://mydbuser:mysecretpass@thePGserver/db',
'HOSTNAME': '28b24b724f54', 'PYTHON_VERSION': '3.6.14', 'ENV': 'development',
'PWD': '/', 'HOME': '/root', 'LANG': 'C.UTF-8', 'GPG_KEY': '0D96DF4D4110E5C43FBFB17F2D347EA6AA65421D',
'TERM': 'xterm', 'SHLVL': '1', 'PYTHON_PIP_VERSION': '21.2.4',
'PYTHON_GET_PIP_SHA256': 'fa6f3fb93cce234cd4e8dd2beb54a51ab9c247653b52855a48dd44e6b21ff28b',
'PYTHON_GET_PIP_URL': 'https://github.com/pypa/get-pip/raw/c20b0cfd643cd4a19246ccf204e2997af70f6b21/public/get-pip.py',
'PATH': '/usr/local/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin', '_': '/usr/local/bin/python'
})
Looks good. You can see that DATABASE_URL and ENV are now part of our env vars, as well as some other predefined
variables that your operating system and/or install programs have configured.
Let’s really update the code now:
# Taken from: https://fastapi.tiangolo.com/advanced/async-sql-databases/?h=async+datab#import-and-set-up-sqlalchemy
# This is a new import needed to use env vars
import os
import databases
from fastapi import FastAPI
# Now, we only need to define DATABASE_URL once, and it no longer contains
# sensitive information.
DATABASE_URL = os.environ.get('DATABASE_URL')
# We should also check if our environment wasn't set up properly and raise if
# `DATABASE_URL` wasn't set
if not DATABASE_URL:
raise AssertionError('DATABASE_URL not configured or detected. '
'Please check your environment variables.')
database = databases.Database(DATABASE_URL)
# We can also do specific things if our app is running in development mode with this variable
IS_DEVELOPMENT = os.environ.get('ENV') == 'development'
if IS_DEVELOPMENT:
print('My app is running in development mode')
# Do other things... like set up local logging, connect to services only available on your local environment.
IV. Backing services
Treat backing services as attached resources https://12factor.net/backing-services
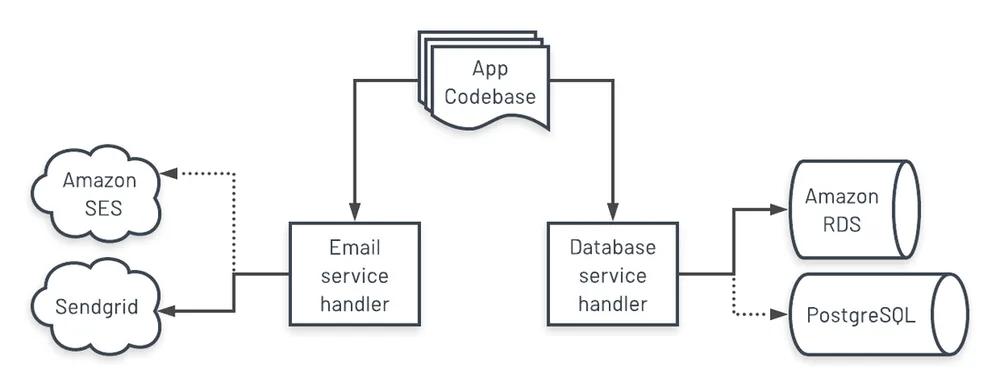
Taken from the official Twelve-factor App page:
A backing service is any service the app consumes over the network as part of its normal operation. Examples include datastores (such as MySQL or CouchDB), messaging/queueing systems (such as RabbitMQ or Beanstalkd), SMTP services for outbound email (such as Postfix), and caching systems (such as Memcached).
With the legwork done on the previous sections, this is now much easier to manage. Our DATABASE_URL is dynamic and can
be changed whenever we need. On the extreme side, we could even entirely swap out our database system -- provided that
our code's dependencies can handle its query language, schema differences, etc. The last bit may be on the excessive
side as it requires a significant amount of development effort for something your app may never need. Thankfully, there
are frameworks out there that give developers the ability to swap out some resources for free.
Django is one such framework that provides easily swappable email functionality, for
example. On the email backends page we can see
that email backends are easily swappable just by changing the EMAIL_BACKEND setting.
The loose coupling of services gives the application freedom from being tied down to a specific service, however, this comes at a cost. In an ideal scenario, a developer would (hopefully) not have to plan to use MySQL, PostgreSQL and Oracle at the same time. They would have a single database system with its credentials in an env var that changes depending on the current environment. At the other extreme, it's unreasonable to expect a project to be able to handle many external services just to conform to this "rule".
To be continued!
This post covered sections I-IV of the Twelve-Factor App methodology. Hopefully, this has given you more insight on some steps to take in order to make an app more flexible and scalable. In a future blog post, we will cover the next few concepts. Here at Anvil we follow many of these concepts in our development process and we believe that sharing our experiences helps everyone create awesome products.
If you’re developing something cool with PDFs or paperwork automation, let us know at developers@useanvil.com. We’d love to hear from you.
Update
Follow the rest of the completed series below: