




With the abundance of digital content and distractions today, it has become increasingly tricky navigating the path to publishing content online and making sure it gets seen. Search engines have adopted complex and evolving algorithms factoring in a number of metrics to determine a site's ranking on their results page. How do you make sure your content gets seen? To answer this, we look to SEO (search engine optimization).
SEO is the process of improving the metrics search engines look at to increase the ranking of a website in search results. In this post, we'll be diving into how search engines work, the foundations of SEO, and the specific changes you can make on your web app to ensure your content consistently shows up on the front page. We'll be covering the many small but incremental changes you can make that build into a noticeable impact in user experience on your site. The extra steps you take in doing so will naturally translate into search engines prioritizing your content.
Search engines: how do they work?
When you type 'cats' into Google images, the search engine returns a never-ending gallery of lovely cat images. Every one of these images are known to the search engine because they have been discovered prior by one of Google's web crawlers. This step of discovering webpages by search engines is called crawling. Web crawlers work by visiting links found in online content, and are crawling the internet nonstop to discover newly published websites.
Next comes indexing. Upon discovering a webpage, web crawlers must parse the data to make sense of what the page is about. Indexing involves analyzing the text, metadata, images, and video files embedded into webpages. The results are stored into a gigantic database belonging to the search engine called the index.
The last step is serving. Based on the input given by the user, which in our case is 'cats', search engines query, filter, and return the most relevant webpages from its index. Serving also takes into account the user's information such as location, language, and search history.
When thinking about SEO, we must consider all of these steps: crawling, indexing, and serving. We need to make it easy for search engines to do their job every step of the way. So, our web app needs to be discoverable, easy to understand, and descriptive. Once search engines find it easily, humans will too.
Increase crawl accessibility
Crawl accessibility is important for the discoverability of your website to web crawlers, and the best way of improving that metric is providing sitemaps. Crawlers automatically traverse through webpages regardless of whether sitemaps are provided, but including them provides a number of advantages. First, pages listed in sitemaps are prioritized by crawlers, giving your webpages earlier exposure and more frequent indexing by search engines. This is especially important if your content is rapidly evolving or not close in proximity to sites with heavy traffic. Second, sitemaps enable the communication of additional information to crawlers, such as update frequency and image or video metadata. Providing crawlers with more data is especially helpful for pages with lots of non-textual content, as crawlers typically rely on text for context.
There are several formats for sitemaps: XML, RSS, and text. Different search engines may accept different formats.
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>http://www.example.com/foo.html</loc>
<lastmod>2020-12-04</lastmod>
<changefreq>monthly</changefreq>
<priority>0.9</priority>
</url>
</urlset>An example of a sitemap in XML format.
As you can see, the code snippet shown communicates to crawlers about the date the webpage was last modified, the likely frequency of changes to the page, and priority of the webpage's URL relative to other pages on the domain.
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:image="http://www.google.com/schemas/sitemap-image/1.1">
<url>
<loc>http://example.org/page1.html</loc>
<image:image>
<image:loc>http://example.org/image1.jpg</image:loc>
</image:image>
</url>
<url>
<loc>http://example.org/page2.html</loc>
<image:image>
<image:loc>http://example.org/image2.jpg</image:loc>
<image:caption>Cats in a pet-friendly office</image:caption>
<image:geo_location>San Francisco, CA</image:geo_location>
<image:title>Office cats</image:title>
<image:license>http://example.org/image-license</image:license>
</image:image>
</url>
</urlset>An example sitemap for two webpages with images in XML format.
Visit this page to learn more about sitemaps and its documentation.
Prevent crawling on irrelevant data
In contrast to encouraging crawling, we need rules to disable crawlers from accessing sensitive, duplicate, or unimportant content. There are numerous scenarios where we want content hidden. There may be pages with private data on your domain you want hidden from search results. In addition, it's good practice to prevent crawlers from seeing repeated content in your web app, as it can be mistaken for spam thus lowering your ranking in search results. Your webpage may have also embedded content from third party sites which can be irrelevant to your topic.
Multiple approaches are available for hiding content from search engines, such as removing the content directly, requiring passwords for certain webpages, or using the noindex directive. Adding a robots.txt file to your web app is the most flexible approach.
User-agent: Googlebot
Disallow: /private/media/
User-agent: *
Allow: /
Sitemap: http://useanvil.com/sitemap.xmlAn example robots.txt file
The above example prevents Google search's web crawler from accessing routes under /private/media/, but all other visitors are given full site access. It's important to allow crawlers access to JavaScript, CSS, and image files with the exception of sensitive data to avoid negative impacts on indexing. And finally, the last line tells the crawler where the sitemap can be found.
The file must be named robots.txt and placed at the root of the website host for crawlers to find. robots.txt works by specifying rules, with each rule involving a group specified using User-agent and their permissions specified using Allow or Disallow. Only one rule may apply to a group at a time.
For more information regarding robots.txt files, refer to these docs.
noindex directive
Besides the robots.txt approach, using the noindex directive is just as effective. noindex can be placed within a meta tag in HTML or an HTTP response header, telling web crawlers indexing the webpage to prevent the page from being shown in search results.
<head>
<title>404 Page not found</title>
<meta name="robots" content="noindex">
</head>
<body>
…
</body>404 page should not be shown in search results
HTTP/2 200 OK
…
X-Robots-Tag: noindexResponse body will not be shown in search results. Body can include HTML, image, video, PDF files.
Refer to this page for more information.
Return helpful HTTP status codes
Web crawlers rely on status codes to determine whether a page should be crawled and if it contains meaningful content. Make use of '301' (moved permanently), '401' (unauthorized), or '404' (not found) statuses so crawlers know how to update the index. Google's web crawler, for example, doesn't save webpages that respond with 4xx or 5xx into the index.
Make indexing easy
Once web crawlers have found your website, you want your webpages to be easy to understand. This involves using concise and unique page titles and descriptions. Each webpage should have a title that is focused on what the content is about and is distinguishable. It's also a good idea to include the business name or location if applicable.
Make use of title and meta tags. Titles should include seven to eight words at most, to avoid any text cut off when shown in search results. Descriptions should include a hook to grab users' attention and get clicks. Having a one to three sentence description is optimal.
<head>
<title>Minimizing webpack bundle size - Anvil</title>
<meta name="description" content="Learn how to minimize your Webpack bundle size by following these best practices, ensuring an optimal user experience.">
</head> First page on Google results
First page on Google results
Performance
Besides the basics such as title and description, user experience plays a huge role. Factors such as performance and web accessibility belong under that category. Metrics such as 'first contentful paint' and 'time to interactive' factor into whether users will remain on the site. You can gather these metrics for your web app using Lighthouse made available by Google.
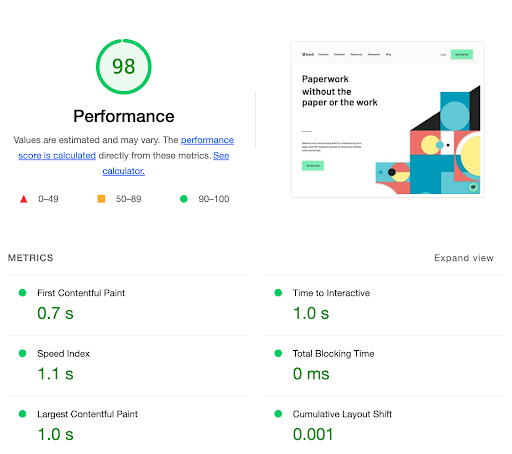 Performance metrics for Anvil's main page
Performance metrics for Anvil's main page
You can improve your performance metrics by compressing images, decluttering your files, code splitting, using lighter dependencies, and so on. If you use Webpack to compile your web app, I highly recommend taking a look at my post about Minimizing webpack bundle size, which covers the subject comprehensively with solutions.
Web accessibility
Enabling your content to be accessible to everyone, including those with impairments, can provide a considerable boost to your ranking. Best practices to adopt include using header tags (i.e. <h1>, <h2>), setting alt attributes to images, and providing labels to control elements (e.g. <button>, <checkbox>).
<h1>Yellow Cab Inc.</h1>
<img src="https://yellowcab.com/assets/logo" alt="Yellow Cab Inc. logo">
<h2>Contact us</h2>
<label for="fullName">Full name:</label>
<input type="text" name="fullName">
<button type="submit">Submit</button>Make use of header tags, the alt attribute, and labels.
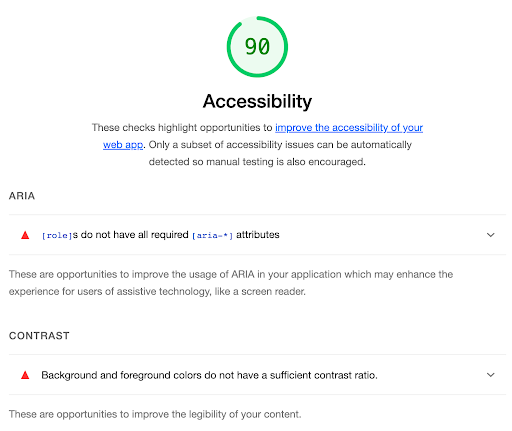 Accessibility metrics
Accessibility metrics
Mobile-friendly
Users expect websites to be usable on mobile, and having a web app that is responsive to that format is crucial for online presence. The most common mobile strategy is responsive web design. With this approach, telling the browser how to adjust content on the viewport is necessary.
<meta name="viewport" content="width=device-width, initial-scale=1.0">The browser is instructed to handle the viewport's dimensions. The width of the webpage is set to the device's width, and with a zoom ratio of 1.0.
A good way to check whether your web app is ready for use on mobile devices is the Mobile-Friendly Test.
Optimize images
Always use the <img> tag to display pictures instead of alternate methods such as CSS. Crawlers respond positively to images having alt attributes in case the image cannot be found. Compress your images so they don't take forever to load and lazy load images that have a high file size. Image filenames also matter, as it gives crawlers context on what the image is. Also, avoid using images as links.
Ex: use 'dog-in-office.png' instead of 'dog1.png'.
Use simple and clear URLs
It may not be apparent, but users do pay attention to the format of URLs. Structure your routes so that they are organized, concise, and clear. Having unstructured URLs can prevent users from clicking and sharing.
Ex: use https://useanvil.com/docs/api/getting-started, not https://useanvil.com/folder-1/file-2.
While on the topic of URLs, I recommend creating a 404 not found page for your web app. It's almost guaranteed that someone will hit a broken link sooner or later.
Provide useful content
I've suggested all the changes you can make to your code to boost your SEO ranking, but the central factor is providing good content. Make sure your blog, service, newsletter, or whatever it is provides information valuable to users. Using keywords, encouraging sharing, adding links to other pieces of useful information, and understanding your audience are all factors to consider.
Summary
We've covered the concept of SEO, the steps involved in displaying a webpage on search results, increasing web app crawl accessibility, optimizing code in handling indexing, and providing a better user experience. We also looked into SEO tools and general web development best practices. With these concepts introduced into your code, you can worry less about whether your content will be discovered.
We've applied these practices to our code at Anvil, and believe sharing our experience helps everyone in creating awesome products. If you're developing something cool with PDFs or paperwork automation, let us know at developers@useanvil.com. We'd love to hear from you.