Most companies don't get stuck on the decision to automate their paperwork. They get stuck right after it.
You've already concluded that building PDF or e-signing infrastructure in-house isn't worth it. You bought a platform. Good call. But there's a part of the project nobody scoped on the way in: someone still has to take your hundreds of blank forms and turn them into structured, fillable templates — every field found, named, typed, and mapped back to your own data model. That work is real, it's repetitive, and it almost always lands on an engineering team that's booked a quarter out.
So the library that was supposed to ship "soon" sits behind the roadmap. We've watched this happen enough times — especially with insurers and other large, regulated organizations — that we decided to just do that part for you.
The actual bottleneck isn't the PDFs. It's the mapping.
Filling a PDF over an API is a solved problem. The hard part of a real document library is consistency at scale: making sure the same piece of information lands in the right place on every form, and that it's named the same way everywhere so your systems can actually drive it.
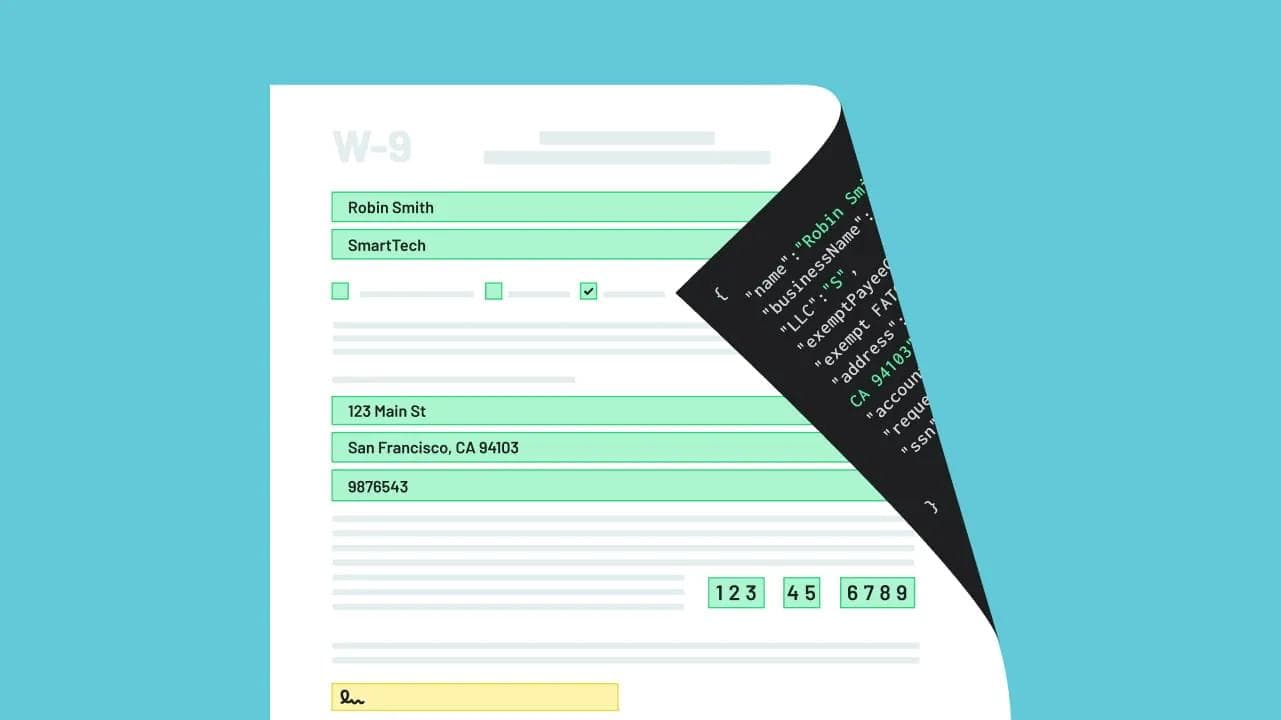
Take a single value — a policyholder's name. Across an insurance form set it might be Named Insured on one ACORD form, Insured Name on the next, and Applicant Full Name on a supplemental. Multiply that by a few hundred fields across a few hundred forms and you don't have a data problem, you have a mapping project. That mapping is the library. It's also the least fun thing to ask a senior engineer to spend a month on.
This is exactly what Anvil's Field Aliases were built for: one canonical field name in your system, correctly placed on every document, no matter what each individual form happens to call it. The technology has been there. What we're adding is the team to do the work.
How the PDF Library service works
Send us two things: your blank documents, and whatever you have describing your data fields. A formal schema is great. A spreadsheet of field names is completely fine — and if you work in insurance, we know you have one.
From there:
1. Anvil's Document AI takes the first pass. Every input on every page gets detected, tagged, and typed automatically. The slow, manual part — drawing boxes over fields and labeling them by hand — is done in minutes instead of weeks. This is the same Document AI that already tags PDFs with hundreds of fields across our platform.
2. Our engineers finalize it. AI gets you most of the way; it doesn't get you to production. We review the first pass, fix the edge cases, handle the messy multi-signer and conditional fields, and bind every field to your schema with Field Aliases. The output is a clean, consistent, audit-friendly library — not a pile of one-off templates.
3. You get an API-ready library. When it's done, filling any document in the library is a single request. One field name in your system fills the right box on all of your forms, every time. That's what we mean by data-ready.
Start free, pay when it's production-ready
We know a done-for-you build is the kind of thing that's hard to greenlight on faith, so we've split it.
The pilot is free. Give us a representative sample of your forms and we'll run the AI first pass, so you can see your own documents become a structured, schema-mapped library — at no cost, and with zero integration work on your side. No engineering time from your team just to find out whether this fits.
The finalized build is paid. Once the pilot proves it out, our team takes the full form set the rest of the way: every field mapped, every edge case handled, QA'd, and delivered ready for production.
The point of the free pilot is simple: you shouldn't have to commit budget or developer hours to see whether a data-ready library is real for your documents. See it first.
Built for teams that live in forms
This is aimed squarely at document-heavy, regulated enterprises — and insurance most of all. Carriers, MGAs, and insurtechs already run their document workflows on Anvil; companies like Pathpoint, Vouch, and Ascend chose Anvil precisely because insurance paperwork has more logic, more forms, and more permutations than a generic e-signature tool can handle. The PDF Library service is for the next group: the larger, slower-moving organizations that want the same outcome but can't free up the engineers to get there.
It works just as well for finance applications and disclosures, healthcare intake and consent forms, and HR onboarding packets — anywhere a big library of forms needs to become structured data.
And because the library is built natively on Anvil, nothing is throwaway. The moment it ships, those templates plug straight into PDF fill, Workflows, and Etch e-signatures whenever you're ready to use them.
See your library become data-ready
If turning your forms into structured, schema-mapped, API-ready templates has been sitting on a someday list, this is the way to find out what it actually looks like — without spending a sprint to do it.
Send us a sample set, and we'll show you the rest.